The Compare records section of the workbench lets you compare two records from your duplicate store to see exactly why they were or were not matched as duplicates by the Find duplicates step. This makes it easy to identify potential configuration changes that may be needed.
To begin, enter a search term to find the two records that you would like to compare. The search term can be present in any column of the input records and is case-insensitive. The entire search term doesn't need to match a single record, so for example, you can also enter multiple unique IDs separated by a space.
If it was enabled on the load duplicate store screen, you can also use Lucene query syntax to perform a more specific search. For example, to search for all records that have a forename field starting with "John" and a surname field of "Doe", you could use the search: forename:john* AND surname:doe. When using Lucene query syntax, use the input dataset column names in lowercase as field names.
Once you have carried out your search, you will be presented with a list of records to choose from. Pick the two records that you would like to compare by selecting the checkbox to the left of each record and then click the Analyze button.
You will then be able to view each record in its standardized form so you can see the final values used by the Find duplicate step to determine if the two records are duplicates. The following example shows two records after they have been standardized:
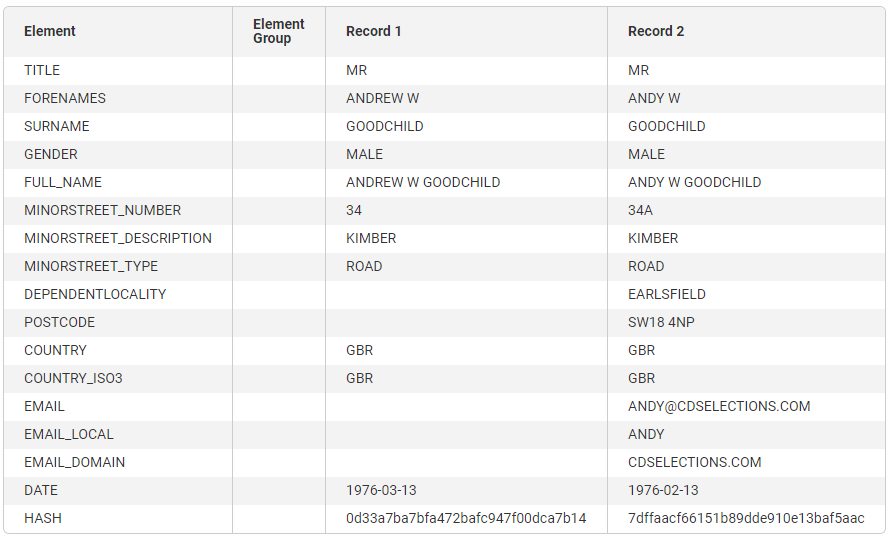
Below standardization, you will find a comparison of each of the generated blocking keys. A blocking key highlighted in green means this blocking key resulted in the two records being scored together. If no blocking keys are highlighted, it means the two records did not reach the scoring stage and will not be considered a match regardless of how they are evaluated against the match rules.
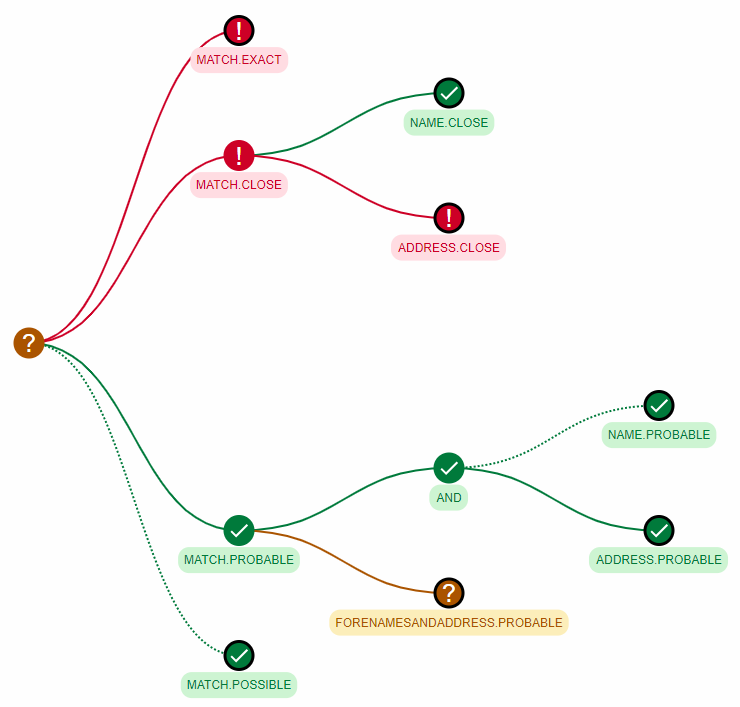
The visualize rules section shows how the two selected records are evaluated against the rules. The leftmost nodes represent the different match levels, each of which can be expanded by clicking on them to show the tree of rules which were evaluated to cause the pair of records to either be matched or not matched. You can further expand any of the rule nodes to see the sub-rules which compose that rule for a complete breakdown of the final match result.
There are four different rule nodes:
In addition, an AND node is used to represent the logical AND operation for rules. All rule nodes directly following an AND node must pass for that node to be considered a pass.
In the following example: